



















































Det är känt att program med grafiskt gränssnitt är bekvämare att använda, eftersom de är utformade för höga krav, plus terminalen gör att du kan lösa vissa uppgifter mycket snabbare. Så det finns ett verktyg wc, det kan räkna antalet rader i en fil. Antalet rader berättar inte mycket, men i fallet när flera kommandon kombineras kan du räkna raderna med hänsyn till nödvändiga parametrar. Hur räknar man rader i en Linux-fil? Låt oss lyfta fram ett par enkla men effektiva exempel på att använda grep-, sed- och awk-kommandon.
Hitta antalet rader i en Linux-fil
Vi har redan tittat på WC-kommandot, nu bör vi bekanta oss med en av dess nyckelparametrar -l. Den räknar övergångar till en ny rad, det vill säga hela raden räknas, inklusive tomma rader. Kommandot klarar uppgiften snabbare än alla andra, men bara vissa strängar är möjliga - med ett givet villkor.
$ wc -l name_file
$ grep -c $ name_file
$ sed -n $= name_file
$ awk 'END{ print NR }' name_file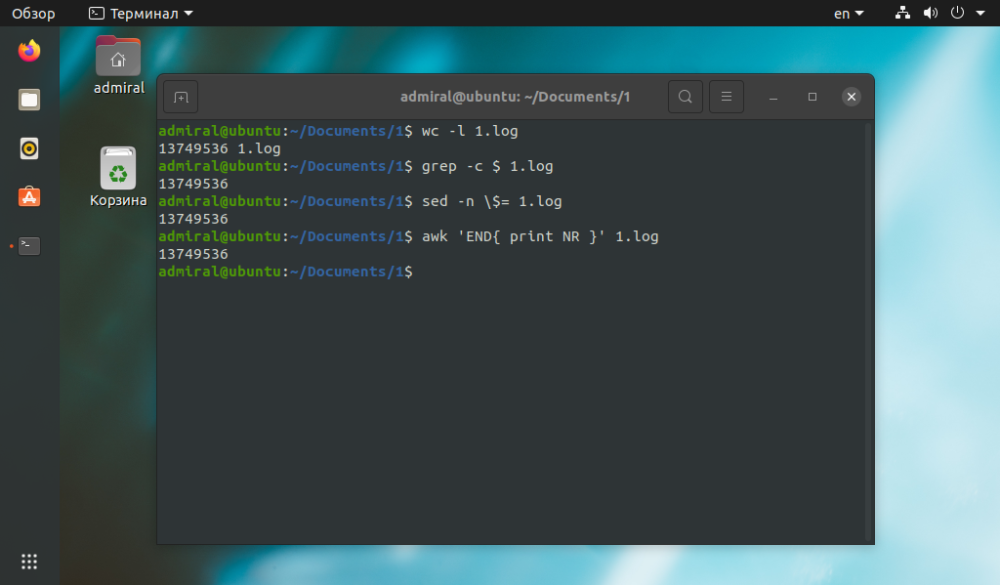
Som vi kan se är resultatet detsamma, men kommandot wc tog kortare tid att slutföra uppgiften. De andra kommandona är tillämpliga för komplexa frågor. Med kommandot grep kan du hitta strängar med enbart text: grep -c 'text' filnamn.
$ grep -c 'text' file_name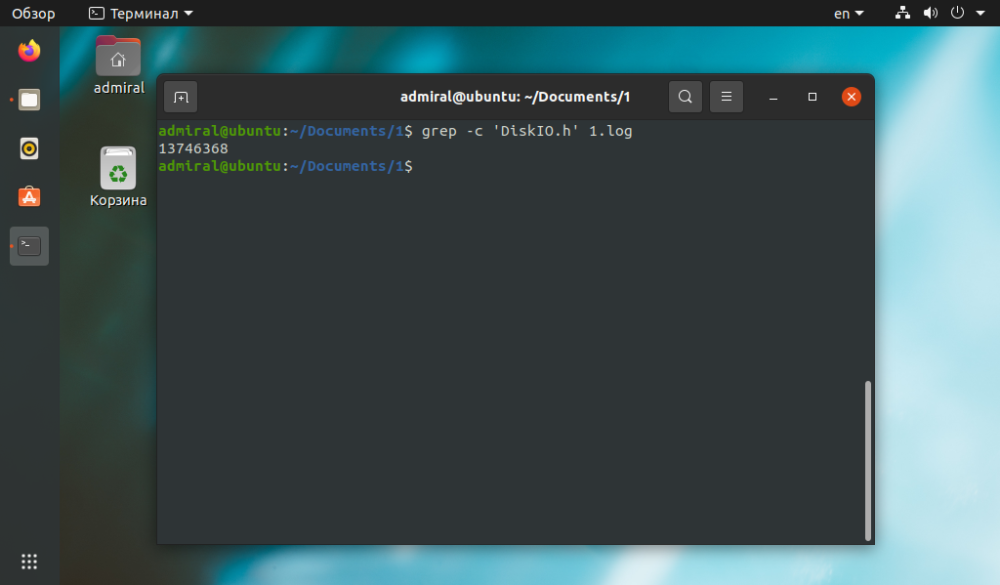
Kommandot grep hanterar reguljära uttryck, så att du kan kombinera flera AND-, OR-, NOT-villkor.
När sed utför textbehandling, men det är mycket enklare att utföra en slutlig radräkning med kommandot wc. Du kan ta bort alla rader som är mindre än tre tecken långa. och komplexa fall räknas utan kommentarer.
$ sed -r '/^.{,3}$/d' file_name | wc -l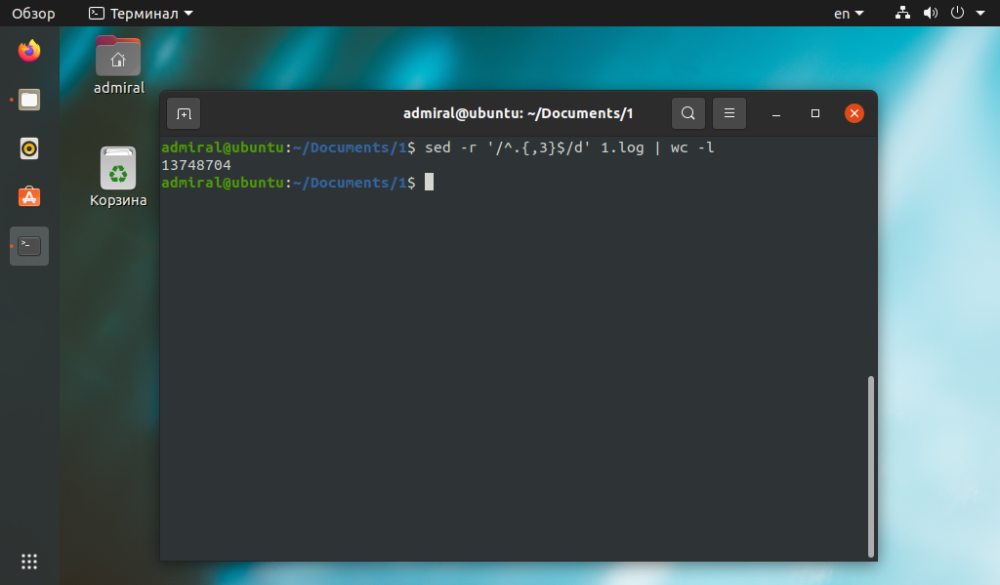
Om uppgiften är enkel kan den göras på andra sätt. Kommandot awk blir enklare och lättare att förstå.
$ awk 'length >3' file_name | wc -l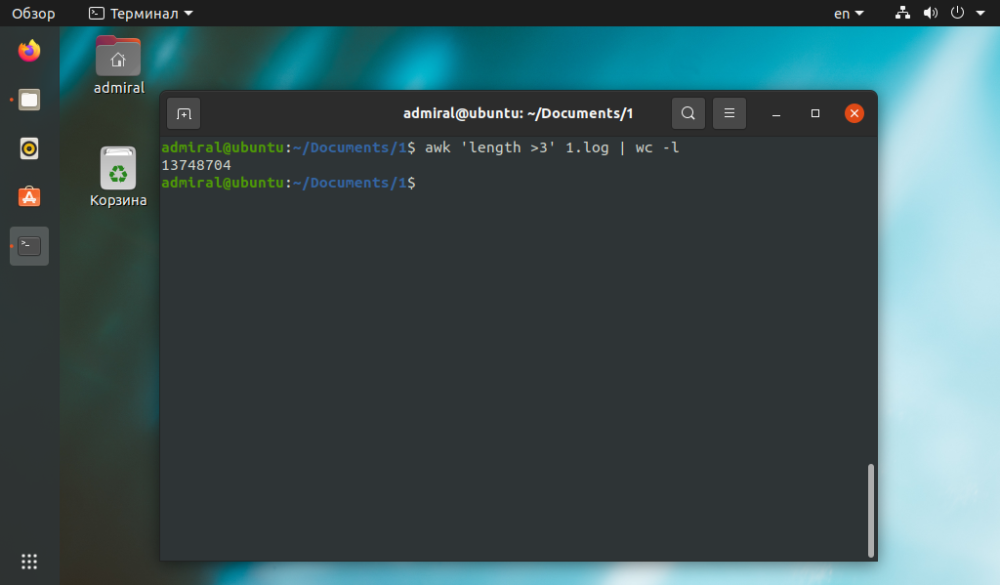
För ett visuellt exempel på awk-kommandot, låt oss utföra strängräkning medan vi söker efter det önskade värdet i csv-tabellfilen.
I exemplet räknar vi antalet rader där värdet för den andra parametern är mer än 50.
$ awk '$2+0 > 50' file_name | wc -l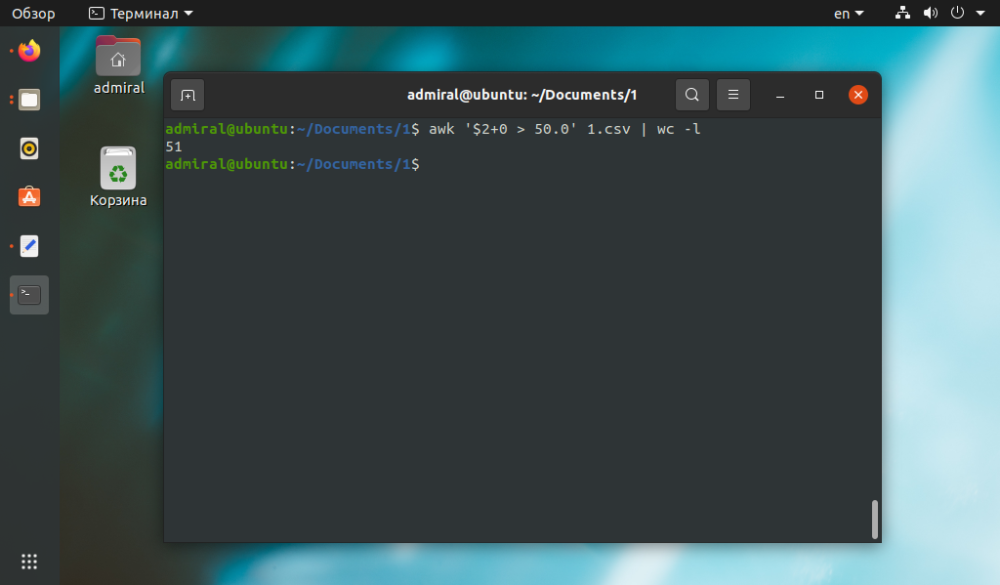
Lägg till 0 i uttrycket för att ta bort alla icke-numeriska uttryck.