



















































Det er kjent at programmer med grafisk grensesnitt er mer praktiske å bruke, fordi de er designet for høye krav, pluss at terminalen lar deg løse visse oppgaver mye raskere. Så det er et verktøy wc, det kan telle antall linjer i en fil. Antall linjer forteller ikke mye, men i tilfelle når flere kommandoer kombineres, kan du telle linjene, med tanke på de nødvendige parametrene. Hvordan telle linjer i en Linux-fil? La oss fremheve et par enkle, men effektive eksempler på bruk av grep-, sed- og awk-kommandoer.
Finne antall linjer i en Linux-fil
Vi har allerede sett på WC-kommandoen, og nå bør vi gjøre oss kjent med en av dens nøkkelparametere -l. Den teller overganger til en ny linje, det vil si at hele linjen telles, inkludert tomme linjer. Kommandoen takler oppgaven raskere enn alle de andre, men bare visse strenger er mulige - med en gitt betingelse.
$ wc -l name_file
$ grep -c $ name_file
$ sed -n $= name_file
$ awk 'END{ print NR }' name_file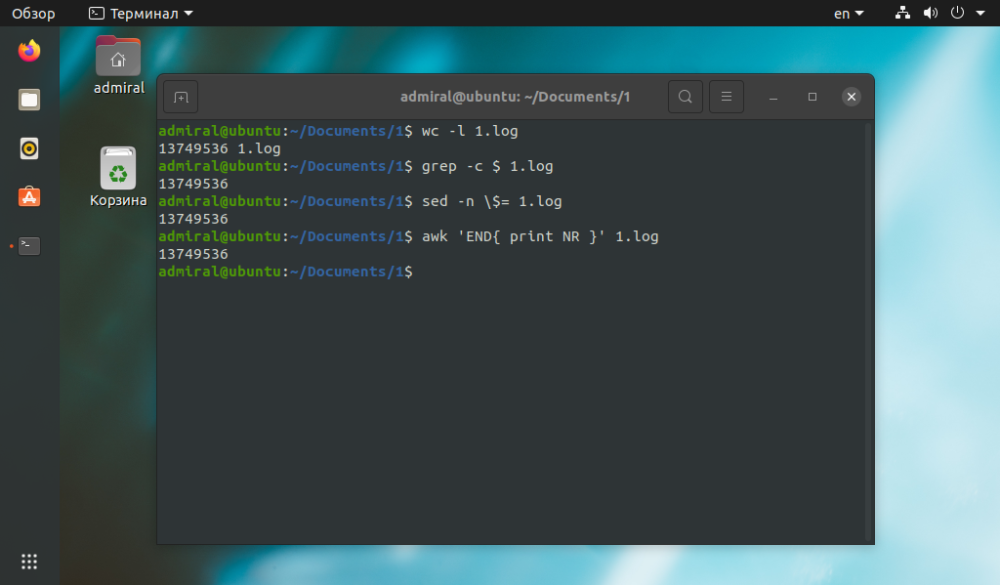
Som vi kan se, er resultatet det samme, men wc-kommandoen tok kortere tid å fullføre oppgaven. De andre kommandoene kan brukes til komplekse spørsmål. Med grep-kommandoen kan du finne strenger som bare inneholder tekst: grep -c 'text' file_name.
$ grep -c 'text' file_name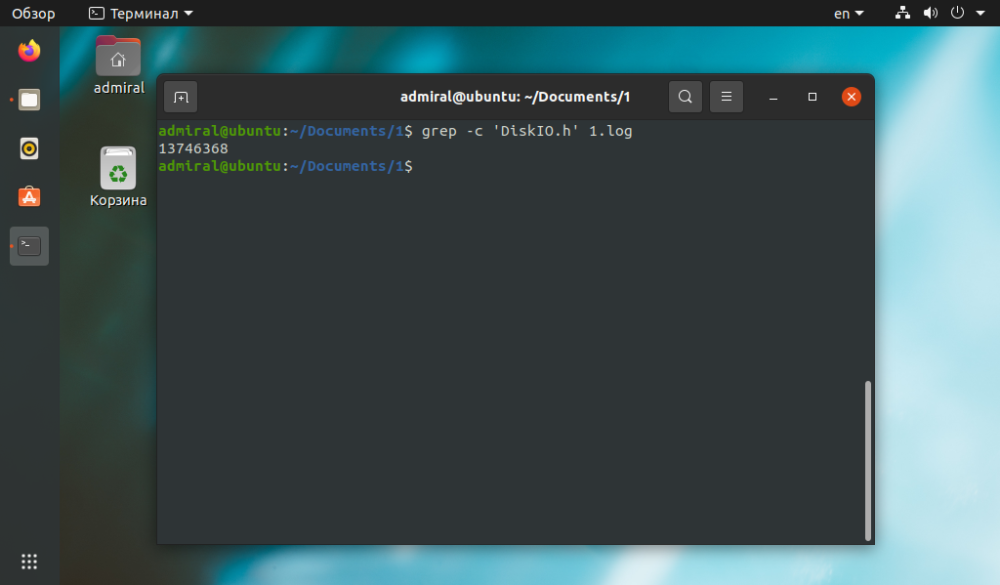
grep-kommandoen håndterer regulære uttrykk, slik at du kan kombinere flere AND-, OR-, NOT-betingelser.
Når sed utfører tekstbehandling, men det er mye enklere å utføre en endelig linjetelling med wc-kommandoen. Du kan slette alle linjer som er mindre enn tre tegn lange. og komplekse tilfeller telles uten kommentarer.
$ sed -r '/^.{,3}$/d' file_name | wc -l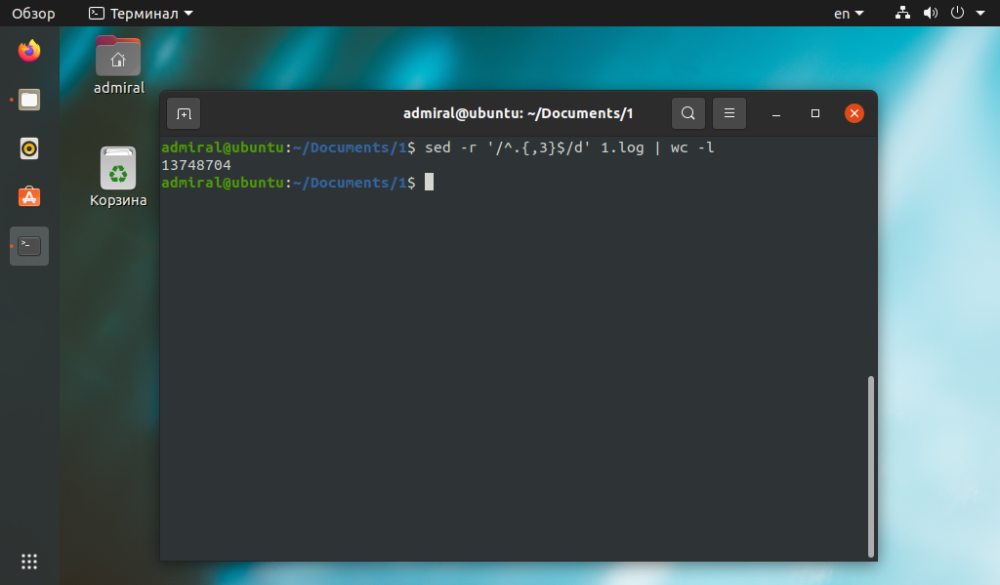
Hvis oppgaven er enkel, kan den gjøres på andre måter. Da blir awk-kommandoen enklere og lettere å forstå.
$ awk 'length >3' file_name | wc -l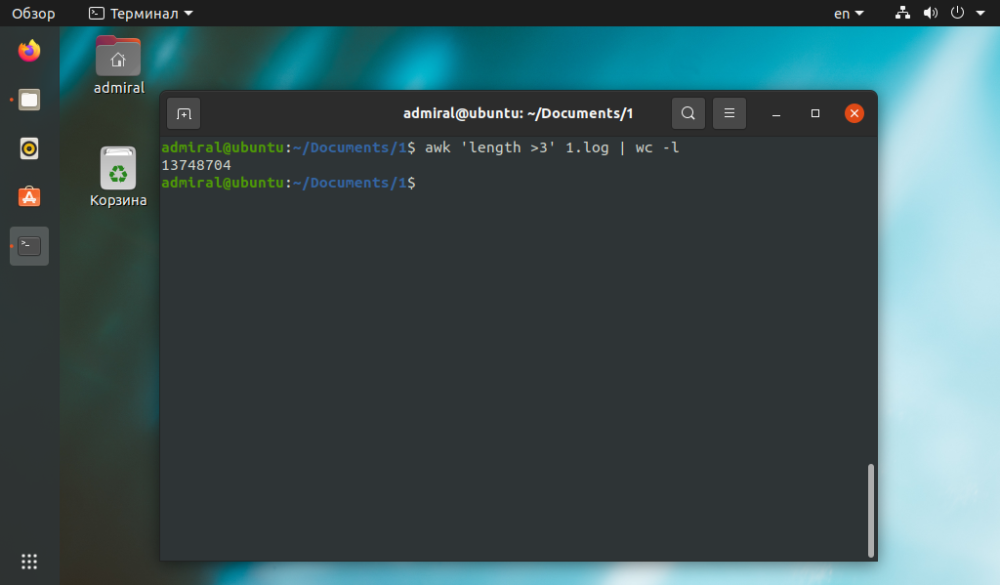
For å få et visuelt eksempel på awk-kommandoen, la oss telle strenger mens vi søker etter den ønskede verdien i csv-tabellfilen.
I eksemplet teller vi antall rader med verdien av den andre parameteren mer enn 50.
$ awk '$2+0 > 50' file_name | wc -l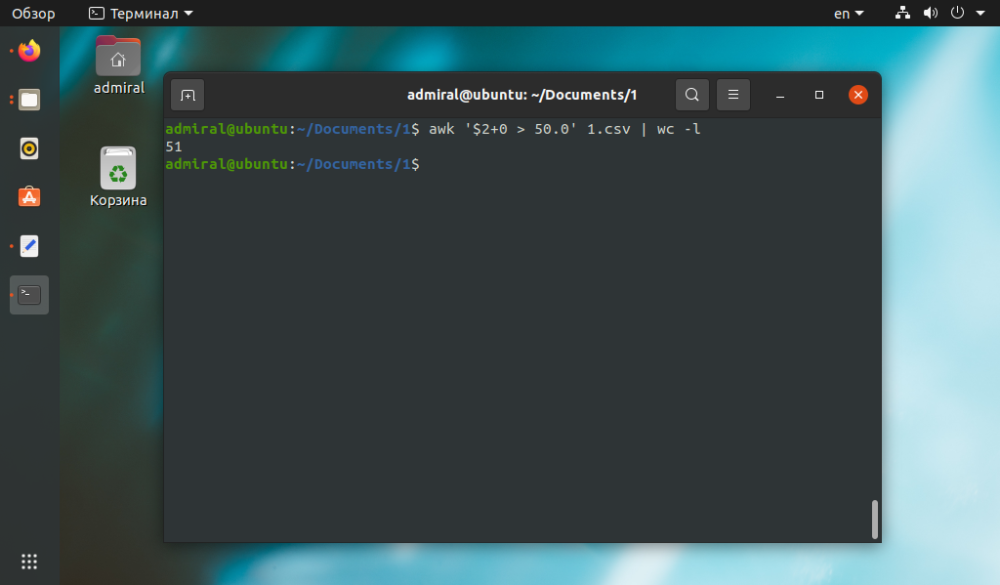
Legg til 0 i uttrykket for å fjerne alle ikke-numeriske uttrykk.