



















































Je známe, že programy s grafickým rozhraním sú pohodlnejšie na používanie, pretože sú navrhnuté pre vysoké požiadavky, a navyše terminál umožňuje riešiť určité úlohy oveľa rýchlejšie. Existuje teda utilita wc, ktorá dokáže spočítať počet riadkov v súbore. Počet riadkov veľa nepovie, ale v prípade, že sa kombinuje niekoľko príkazov, môžete počítať riadky s prihliadnutím na potrebné parametre. Ako spočítať riadky v súbore v systéme Linux? Uveďme si niekoľko jednoduchých, ale účinných príkladov použitia príkazov grep, sed a awk.
Zistenie počtu riadkov v súbore Linux
Príkaz WC sme si už priblížili, teraz by sme sa mali oboznámiť s jedným z jeho kľúčových parametrov -l. Počíta prechody na nový riadok, to znamená, že sa počíta celý riadok vrátane prázdnych riadkov. Príkaz si s touto úlohou poradí rýchlejšie ako všetky ostatné, ale je možné použiť len niektoré riadky - s danou podmienkou.
$ wc -l name_file
$ grep -c $ name_file
$ sed -n $= name_file
$ awk 'END{ print NR }' name_file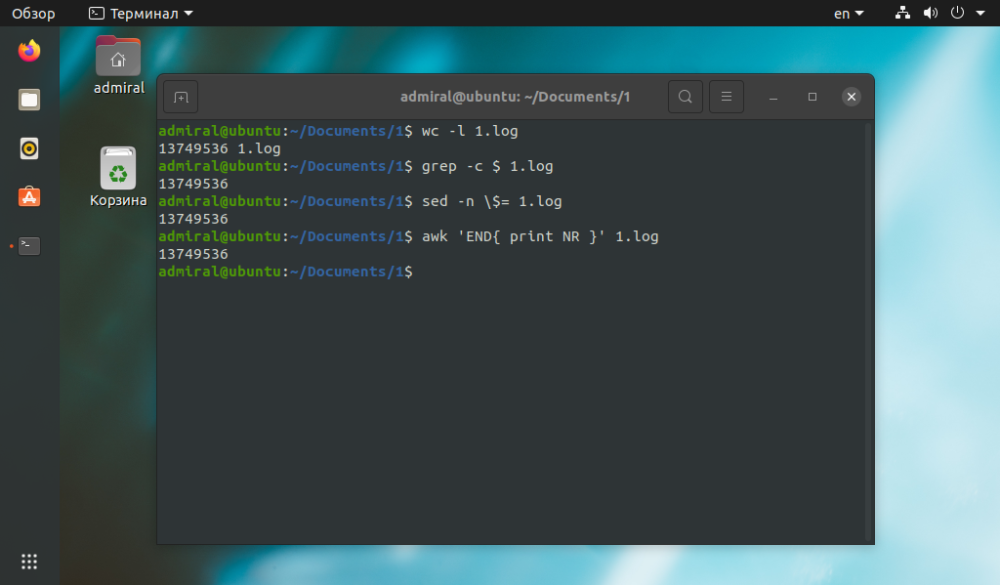
Ako vidíme, výsledok je rovnaký, ale príkaz wc potreboval na splnenie úlohy menej času. Ostatné príkazy sú použiteľné pre zložité dotazy. Príkaz grep umožňuje nájsť reťazce len s textom: grep -c 'text' názov_súboru.
$ grep -c 'text' file_name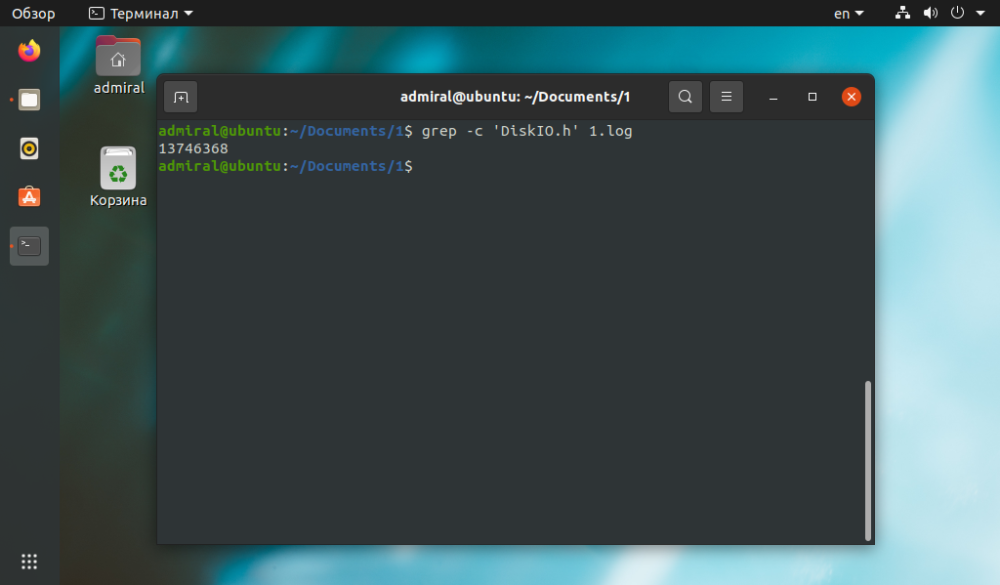
Príkaz grep pracuje s regulárnymi výrazmi, takže môžete kombinovať viacero podmienok AND, OR, NOT.
Pri príkaze sed sa vykonáva spracovanie textu, ale oveľa jednoduchšie je vykonať konečné spočítanie riadkov pomocou príkazu wc. Môžete vymazať všetky riadky, ktoré majú menej ako tri znaky. a zložité prípady sa počítajú bez komentárov.
$ sed -r '/^.{,3}$/d' file_name | wc -l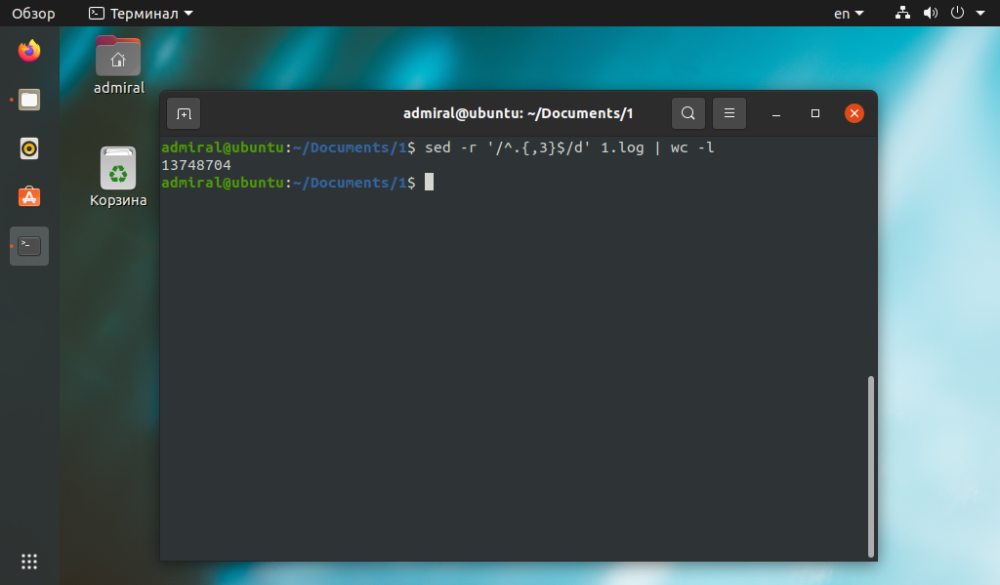
Ak je úloha jednoduchá. možno ju vykonať aj iným spôsobom. Príkaz awk bude jednoduchší a zrozumiteľnejší.
$ awk 'length >3' file_name | wc -l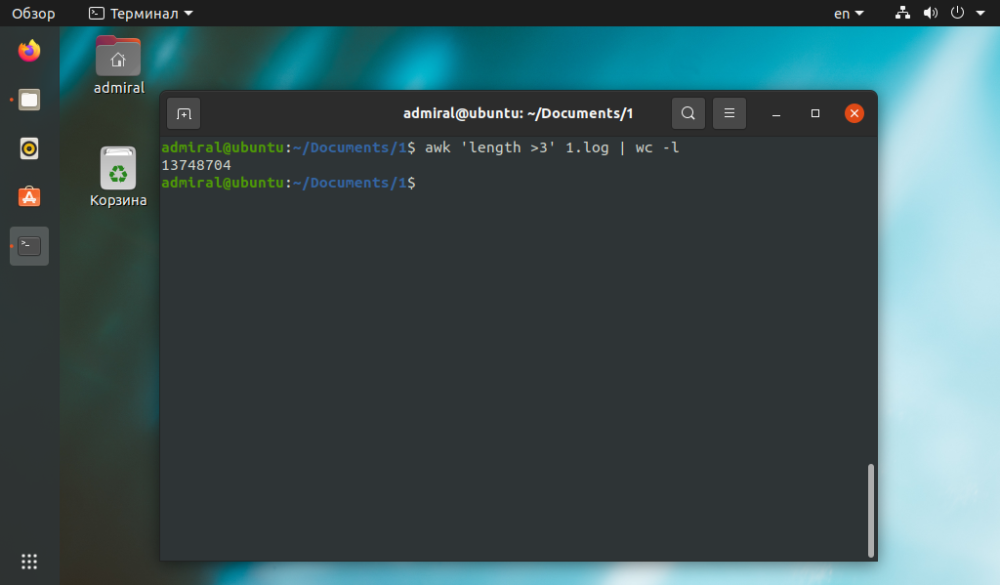
Pre názorný príklad príkazu awk vykonajme počítanie reťazcov pri hľadaní požadovanej hodnoty v súbore tabuľky csv.
V príklade spočítajme počet riadkov s hodnotou druhého parametra väčšou ako 50.
$ awk '$2+0 > 50' file_name | wc -l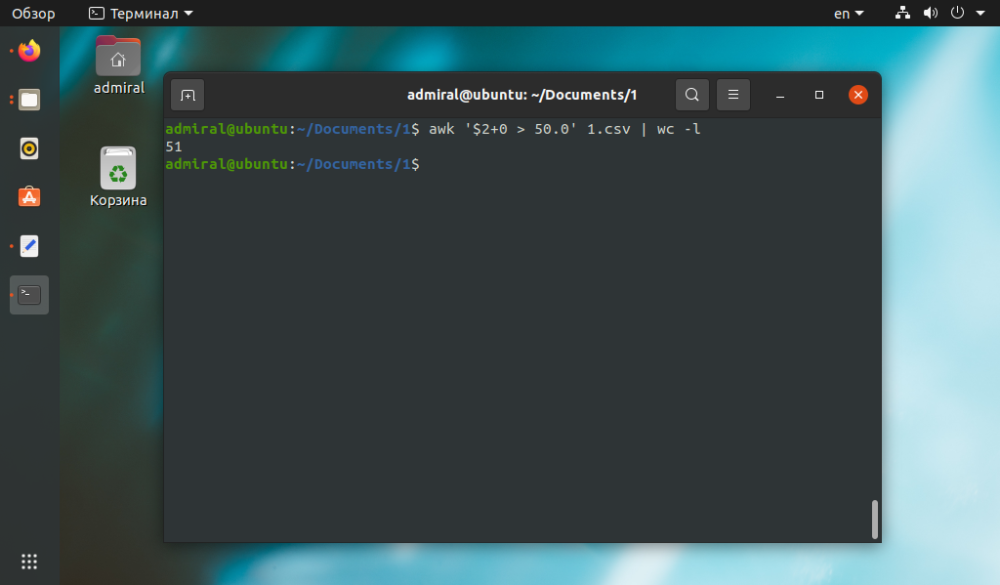
Do výrazu pridajte 0, aby ste odstránili všetky nečíselné výrazy.