



















































Je známo, že programy s grafickým rozhraním se používají pohodlněji, protože jsou navrženy pro vysoké nároky, a navíc terminál umožňuje řešit některé úlohy mnohem rychleji. Existuje tedy utilita wc, která umí spočítat počet řádků v souboru. Počet řádků o ničem moc nevypovídá, ale v případě kombinace několika příkazů můžete počítat řádky s přihlédnutím k potřebným parametrům. Jak spočítat řádky v souboru v Linuxu? Uveďme si několik jednoduchých, ale účinných příkladů použití příkazů grep, sed a awk.
Zjištění počtu řádků v souboru systému Linux
Příkazem WC jsme se již zabývali, nyní bychom se měli seznámit s jedním z jeho klíčových parametrů -l. Ten počítá přechody na nový řádek, to znamená, že se počítá celý řádek včetně prázdných řádků. Příkaz si s úkolem poradí rychleji než všechny ostatní, ale je možné použít jen určité řádky - s danou podmínkou.
$ wc -l name_file
$ grep -c $ name_file
$ sed -n $= name_file
$ awk 'END{ print NR }' name_file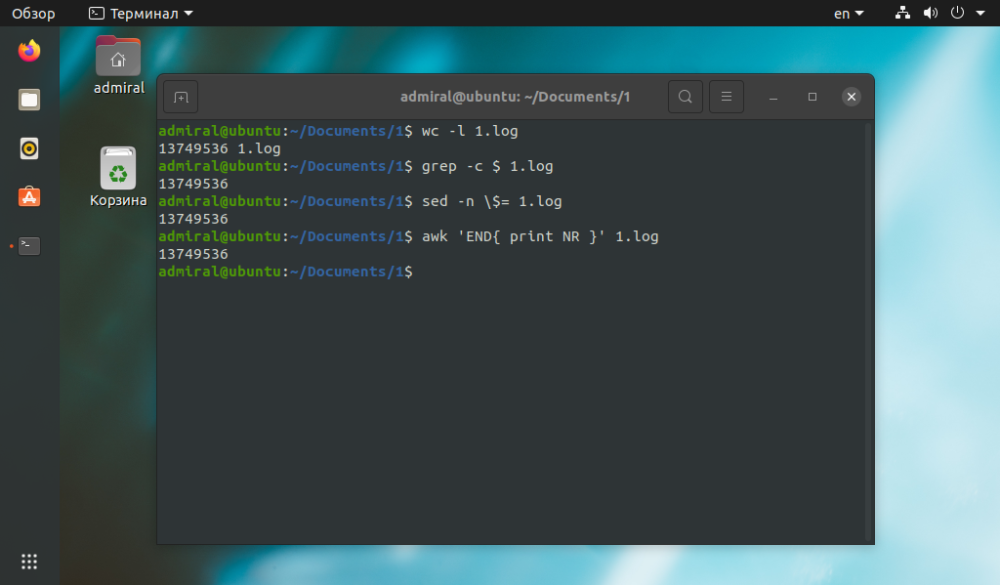
Jak vidíme, výsledek je stejný, ale příkaz wc potřeboval ke splnění úlohy méně času. Ostatní příkazy jsou použitelné pro složité dotazy. Příkaz grep umožňuje vyhledat pouze textové řetězce: grep -c 'text' název_souboru.
$ grep -c 'text' file_name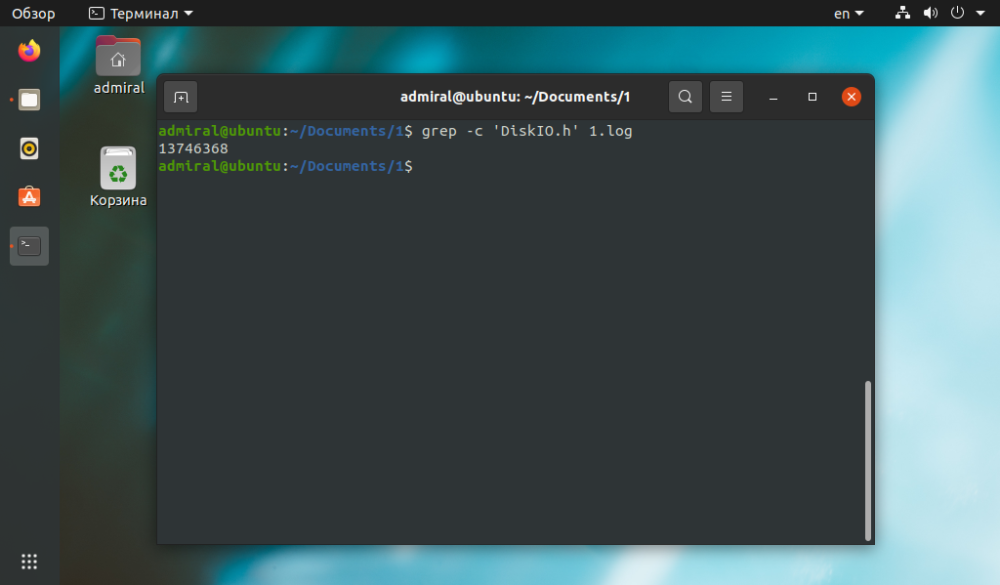
Příkaz grep zvládá regulární výrazy, takže můžete kombinovat více podmínek AND, OR, NOT.
Příkaz sed sice provádí zpracování textu, ale mnohem jednodušší je provést závěrečný počet řádků pomocí příkazu wc. Můžete vymazat všechny řádky, které jsou kratší než tři znaky. a složité případy se počítají bez komentářů.
$ sed -r '/^.{,3}$/d' file_name | wc -l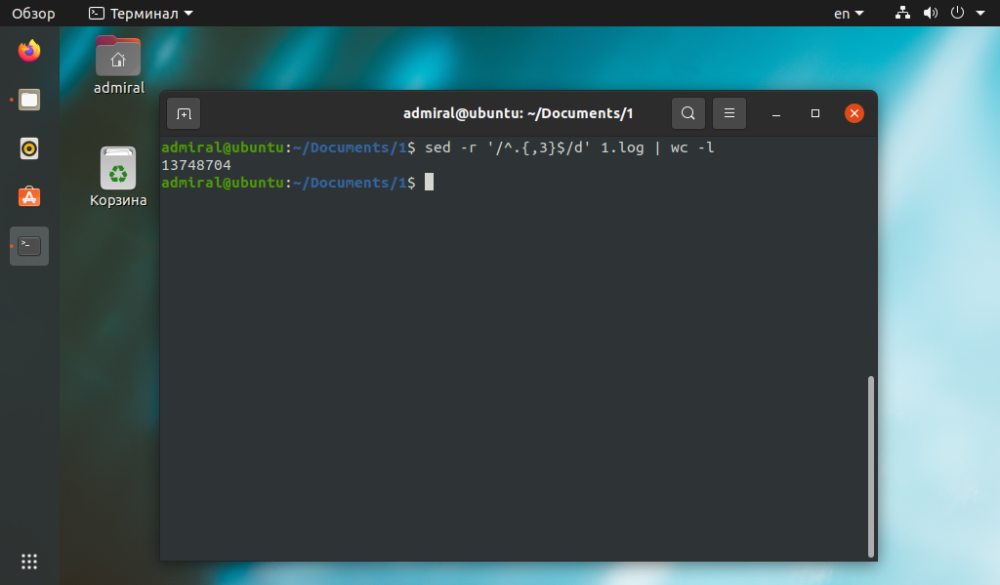
Pokud je úloha jednoduchá. lze ji provést i jinými způsoby. Příkaz awk bude jednodušší a srozumitelnější.
$ awk 'length >3' file_name | wc -l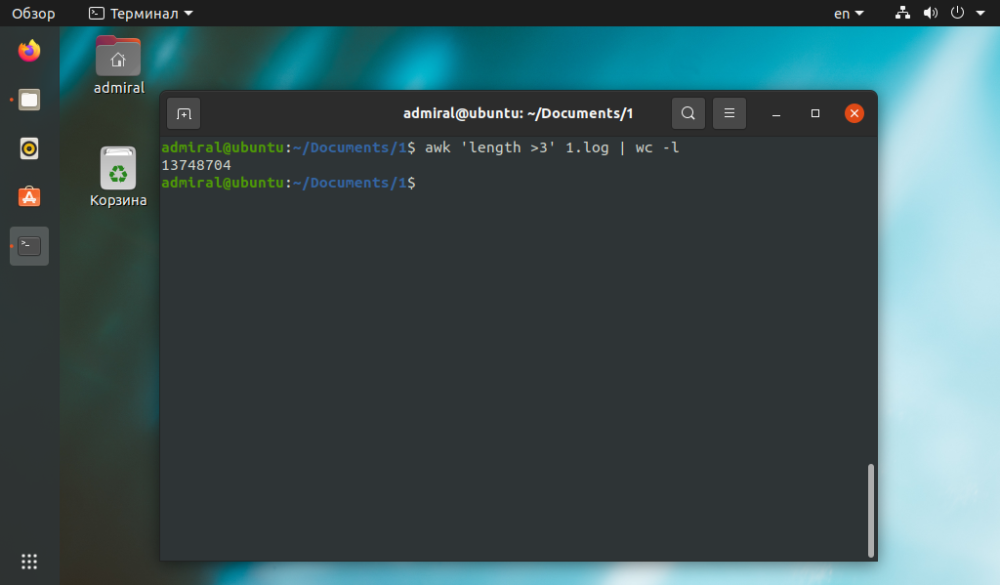
Pro názorný příklad příkazu awk proveďme počítání řetězců při hledání požadované hodnoty v souboru tabulky csv.
V příkladu spočítejme počet řádků s hodnotou druhého parametru větší než 50.
$ awk '$2+0 > 50' file_name | wc -l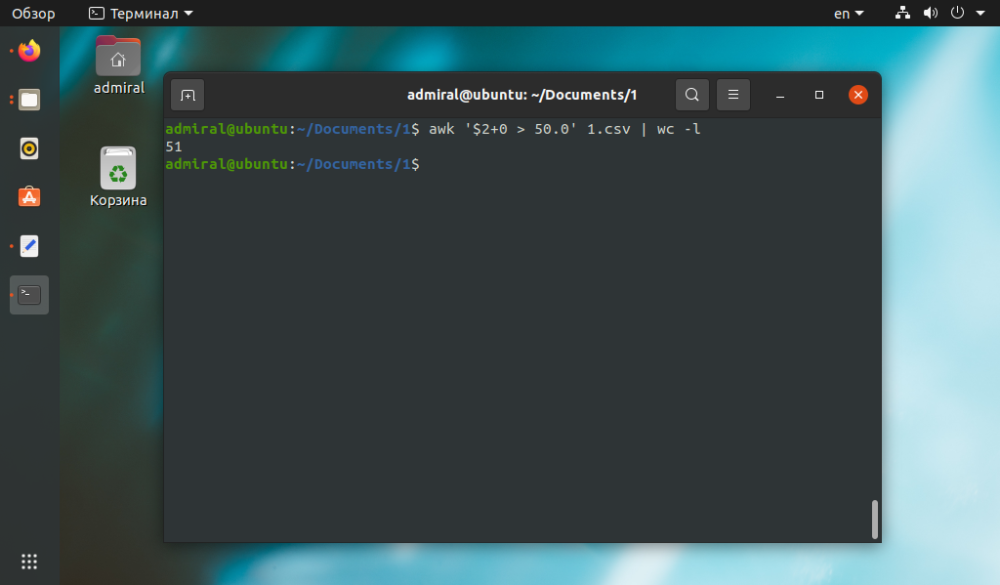
Do výrazu přidejte 0, abyste odstranili všechny nečíselné výrazy.